MANAS平台快问快答
Q:MANAS是怎样工作的?
A:以植物检测为例:
用户通过API或网页终端直接提交检测对象;
检测图片上传到IPFS网络缓存区域;
系统调用分布式部署的植物监测AI模型;
模型调用闲置矿工算力来进行运算;
将运算结果反馈给用户,同时扣取相应的费用;
费用分配给算法提供者和算力提供者;
IPFS上缓存的图片删除。
Q:MANAS平台上服务的工作原理?
A:MANAS上每一个服务,背后都对应着一个算法模型,目前MANAS上公开的几个服务:银行卡识别、证件识别、动物识别、植物识别、人脸识别,这些服务从大类上都属于图形图像识别,而图形图像识别这个人工智能细分领域也正是Steve带领的MATRIX人工智能团队比较擅长的领域。
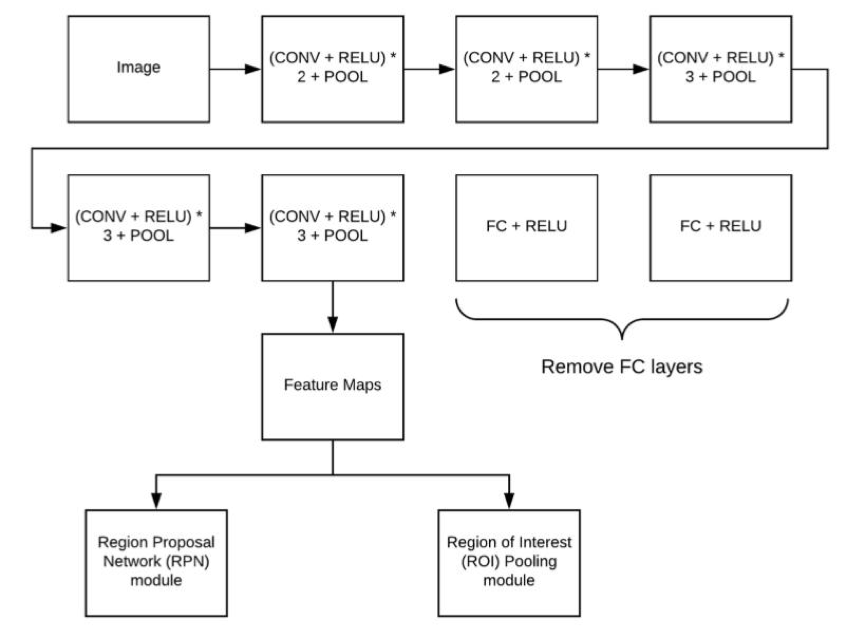
在这几个服务中,MATRIX主要采用了FasterR-CNN网络,这是一个升级的卷积神经网络,工作流程如下:
对于一张输入的彩色图片,首先经过CNN层进行特征提取,MATRIX使用的是预训练好的VGG16网络用于特征提取。VGG网络去掉全连接层,只保留卷积的部分。
卷积层提取完特征之后,对于特征图的数据,分成两部分,分别进入RPN网络(候选区域选择网络),和ROIpooling网络。对于RPN而言,这个网络所做的工作是挑选出图片中可能的候选区域,区分前景和背景。这些信息用来辅助最终的目标检测的决策。
ROIPooling所要做的是收集输入的featuremaps和proposals,综合这些信息后提取proposalfeaturemaps,送入后续全连接层判定目标类别。
最后使用classifer用于做出最后判断。包括图像类别和位置。
整个网络架构如下:
Q:MANAS平台上的服务是怎样训练出来的?
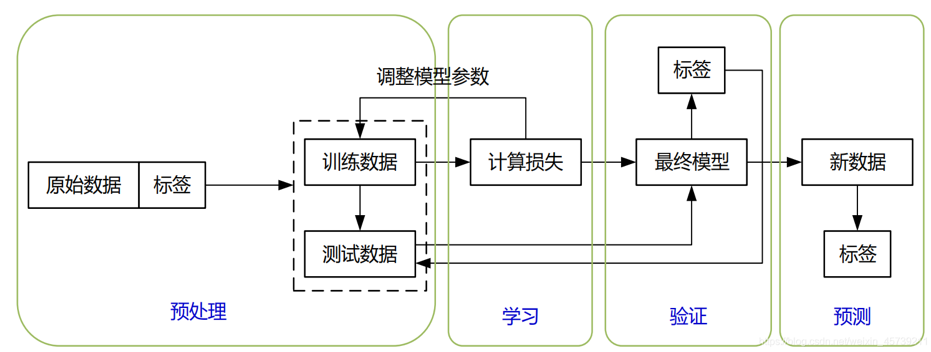
A:MANAS上的服务所对应的的模型的训练过程如下图所示。首先要对数据进行标签化,标签方式由问题确定。对于图像识别问题,标签就是图像的分类;对于目标检测问题,标签要包含所有需要检测的物体在图像中的位置(一般是一个完整包含物体的矩形框)和物体种类。同时,数据还要经过其它预处理过程,例如对数据进行归一化。接下来,就可以开始训练,即确定神经网络各种参数(通常是权重和偏置)的取值。 在训练起步时,这些参数某种概率分布进行随机赋值。然后,我们把数据和标签同时输入神经网络,神经网络根据现在的权重对数据数据进行计算然后输出计算所得的标签。这个标签一般和之前的标签存在一定差距,其中的差距就是就是损失函数。根据损失函数,我们可以通过计算偏导数的方法获得神经网络每个参数对错误的贡献(即梯度),然后根据贡献大小更新权重的取值。这一过程迭代进行,直至损失函数接近0,说明在训练数据上深度神经网络已经能够准确推断。这时,我们需要使用训练集之外的数据检查网络模型的精度,如果精度不足,则需要调整网络结构或者增加训练数据进行训练,直至精度达到要求。
Q:在训练MANAS上面AI服务的模型时,用到了哪些数据?
A:在动植物识别的训练中,我们主要是以“ImageNet”的图片数据库为基础;银行卡、证件几个服务中,我们采用了Alipay等几个可调用训练但不可查询的数据库,以及公安与银行的过期作废证照数据库,同时采用了小样本的训练方式来保证训练质量;在训练面部识别模型中,我们选用了网络的公开数据,以及部分第三方提供的收费志愿者的数据来进行训练。
Q:目前MANAS上的服务都是使用MANTA训练出来的吗?
A:目前MANAS上的服务还都是采用中心化的方式训练出来之后,再做去中心化的部署的,等到MANTA的全部研发与测试工作结束之后,MATRIX团队自身将会改用MANTA来进行模型训练,也欢迎更多的算法科学家使用MANTA训练模型。
Q:MANAS的这些AI服务,比其他平台的服务优势在哪里?
A:除了去中心化、扩展性强、人人可用等以前文章中我们提到的优势之外,MANAS上的图形图像识别的算法比其他平台有一些技术上的创新优势。
一般来说,做图形图像识别,存在最大的问题就是尺度变换多样。比如说对人脸的目标检测而言,一张图片中,人脸有大有小。如何将这些大小不一的图片全部识别出来,并不算太容易。大多数平台采用的方式是滑移窗口和图像金字塔的形式。通过滑移窗口扫描图像,以及图像金字塔的尺度变化来解决这个多尺度检测问题。然而这种方法无论是速度还是检测效果都不算好。MANAS上的服务都是通过引入全卷积神经网络(fully convolutional network)来进行识别,实现了一种端到端的候选区域提取,比起传统的模式大大提升了识别的效率与精准度。